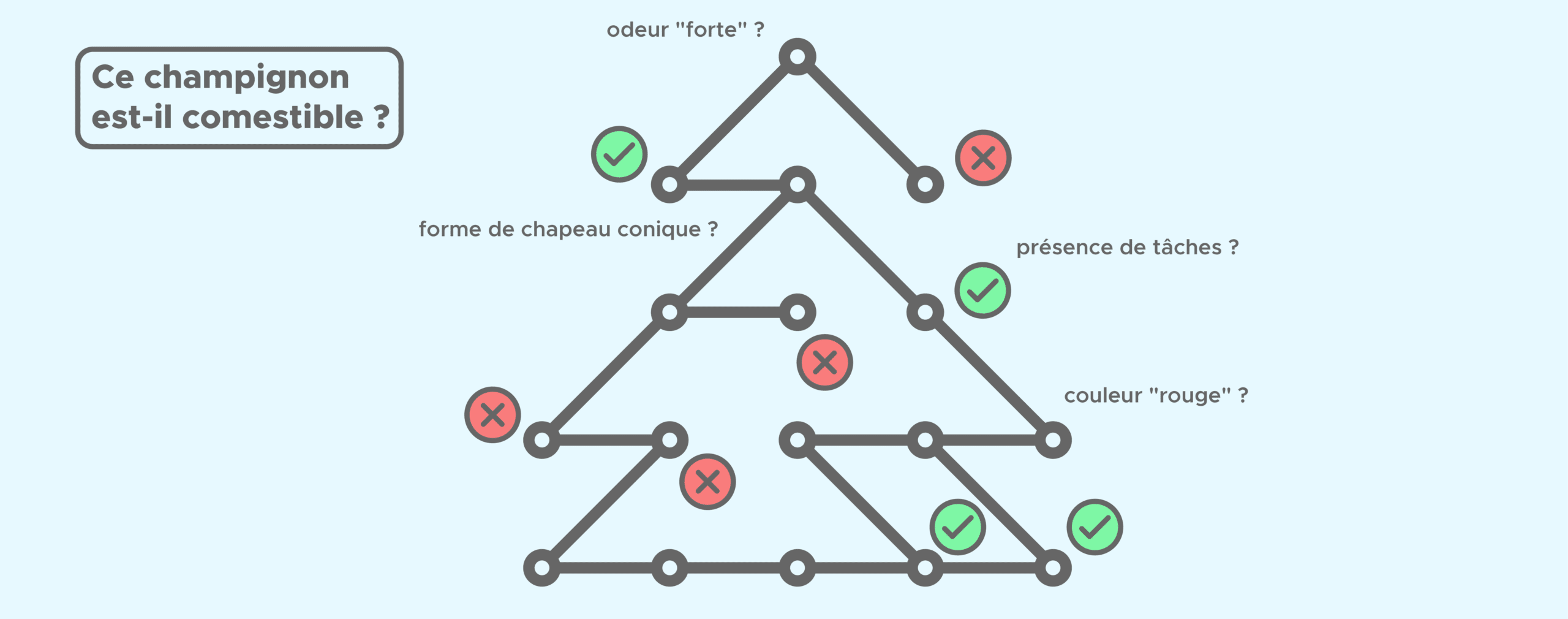
¿Cómo funciona el modelo Random Forest?
Un Random Forest es un conjunto (ensemble) de árboles de decisión combinados con bagging. Al usar bagging, lo que en realidad está pasando, es que distintos árboles ven distintas porciones de los datos. Ningún árbol ve todos los datos de entrenamiento.
¿Cómo funciona Random Forest Python?
Un modelo Random Forest está formado por un conjunto (ensemble) de árboles de decisión individuales, cada uno entrenado con una muestra aleatoria extraída de los datos de entrenamiento originales mediante bootstrapping). Esto implica que cada árbol se entrena con unos datos ligeramente distintos.
¿Qué quiere decir Random Forest?
Random Forest: Bosque aleatorio.
¿Qué es Random Forest Regressor?
Los Bosques Aleatorios es un algoritmo de Machine Learning flexible y fácil de usar que produce, incluso sin ajuste de parámetros, un gran resultado la mayor parte del tiempo.
¿Cómo funciona el modelo Random Forest?
Un Random Forest es un conjunto (ensemble) de árboles de decisión combinados con bagging. Al usar bagging, lo que en realidad está pasando, es que distintos árboles ven distintas porciones de los datos. Ningún árbol ve todos los datos de entrenamiento.
¿Qué quiere decir Random Forest?
Random Forest: Bosque aleatorio.
¿Quién creó Random Forest?
El algoritmo para inducir un random forest fue desarrollado por Leo Breiman y Adele Cutler y Random forests es su marca de fábrica. El término aparece de la primera propuesta de Random decision forests, hecha por Tin Kam Ho de Bell Labs en 1995.
¿Qué pasa si incremento el número de árboles de un Randomforest?
Nótese que Random Forest produce modelos predictivos no descriptivos. El coste de entrenar puede ser alto. El coste computacional de entrenar un modelo de Random Forest aumenta a medida que se incrementa el número de árboles.
¿Qué es algoritmo de aprendizaje no supervisado?
El aprendizaje no supervisado es una de las formas en que Machine Learning (ML) “aprende” los datos. El aprendizaje no supervisado tiene datos sin etiquetar que el algoritmo tiene que intentar entender por sí mismo.
¿Cómo saber si un modelo tiene overfitting?
Hay una señal inequívoca de que un modelo de machine learning sufre overfitting: con el data set de entrenamiento, su porcentaje de acierto ronda el 100%; pero cuando procesa registros nuevos, este último se desploma hasta la mitad o menos.
¿Qué es el analisis supervisado?
El aprendizaje supervisado es una rama de Machine Learning , un método de análisis de datos que utiliza algoritmos que aprenden iterativamente de los datos para permitir que los ordenadores encuentren información escondida sin tener que programar de manera explícita dónde buscar.
¿Qué significa bien random?
Esta palabra se ha convertido en un comodín y es que, según los diccionarios significa: algo aleatorio.
¿Qué es un modelo de Machine Learning?
El Machine Learning es una disciplina científica que ha ganado gran importancia en el mundo tecnológico en tiempos recientes. Es una sub rama de la Inteligencia Artificial y forma parte integral de un número importante de procesos con los que tenemos contacto a diario.
¿Cuándo usar un árbol de decisiones?
Un diagrama de árbol de decisiones te permite evaluar mediante una representación gráfica los posibles resultados, costos y consecuencias de una decisión compleja. Este método es muy útil para analizar datos cuantitativos y tomar una decisión basada en números.
¿Cómo saber si un modelo está Sobreajustado?
Se dice que un modelo estadístico está sobreajustado cuando lo entrenamos con muchos datos. Cuando un modelo se entrena con tantos datos, comienza a aprender del ruido y las entradas de datos inexactas en nuestro conjunto de datos.
¿Qué es el analisis supervisado?
El aprendizaje supervisado es una rama de Machine Learning , un método de análisis de datos que utiliza algoritmos que aprenden iterativamente de los datos para permitir que los ordenadores encuentren información escondida sin tener que programar de manera explícita dónde buscar.
¿Qué hace XGBoost?
XGBoost es un método de aprendizaje automático supervisado para clasificación y regresión y se utiliza en la herramienta Entrenar con AutoML. XGBoost es la abreviatura de las palabras inglesas “extreme gradient boosting” (refuerzo de gradientes extremo).
¿Cómo funciona el modelo Random Forest?
Un Random Forest es un conjunto (ensemble) de árboles de decisión combinados con bagging. Al usar bagging, lo que en realidad está pasando, es que distintos árboles ven distintas porciones de los datos. Ningún árbol ve todos los datos de entrenamiento.
¿Qué quiere decir Random Forest?
Random Forest: Bosque aleatorio.
¿Cómo saber si un modelo está Sobreajustado?
Se dice que un modelo estadístico está sobreajustado cuando lo entrenamos con muchos datos. Cuando un modelo se entrena con tantos datos, comienza a aprender del ruido y las entradas de datos inexactas en nuestro conjunto de datos.
¿Cuál es la diferencia entre bagging y boosting?
Por su parte, a diferencia del bagging (que destaca por su rapidez), el método boosting es una metodología general de aprendizaje lento. En este método se combinan una gran variedad de modelos que se obtienen de un método con poca predicción, con el objeto de dar lugar a un mejor predictor.
¿Cuándo usar boosting?
El boosting es un método utilizado en el machine learning para reducir los errores en el análisis predictivo de datos. Los científicos de datos entrenan el software de machine learning, llamado modelos de machine learning, con datos etiquetados para efectuar predicciones sobre datos no etiquetados.
¿Dónde se aplica el aprendizaje no supervisado?
Las principales aplicaciones del aprendizaje no supervisado están relacionadas en el agrupamiento o clustering de datos. Aquí, el objetivo es encontrar subgrupos homogéneos dentro de los datos. Estos alogoritmos se basan en la distancia entre observaciones.
¿Cómo se clasifican los métodos de aprendizaje no supervisado?
Los algoritmos no supervisados se pueden dividir en diferentes categorías: como los algoritmos de agrupamiento o clústeres y los de asosiación. Complejidad computacional: El Aprendizaje Supervisado es un método más sencillo.
¿Qué es el overfitting y el Underfitting?
Tal vez se pueda traducir overfitting como “sobreajuste” y underfitting como “subajuste” y hacen referencia al fallo de nuestro modelo al generalizar -encajar- el conocimiento que pretendemos que adquieran.
¿Cuáles son los ejemplos de Random Forest?
Por ejemplo, se pueden enumerar las siguientes: En conjuntos de datos pequeños. Random Forest no produce buenos modelos cuando los conjuntos de datos son pequeños. La necesidad de tener que dividir el conjunto de datos en submuestras hace que no se puedan obtener buenas predicciones.
¿Cuál es el punto negativo de Random Forest?
Como punto negativo, en Random Forest no se interpretan los árboles que se construyen. Lo que obtenemos es solamente la importancia de las variables explicativas. Random Forest se utiliza solo para clasificar la importancia de las variables en la predicción de la variables objetivo.
¿Cuál es la diferencia entre Random Forest y árboles de decisión?
Random Forest es permite obtener de una manera fácil y sin la necesidad de realizar suposiciones sobre el conjunto de datos modelos con una alta capacidad predictiva. En su contra se encuentra que no ofrecen la misma capacidad explicativa que lo los árboles de decisión. ¿Te ha parecido de utilidad el contenido?
¿Cuáles son las ventajas y desventajas de un random forest?
Dato que un random forest es un conjunto de árboles de decisión, y los árboles son modelos no-paramétricos, los random forests tienen las mismas ventajas y desventajas de los modelos no-paramétricos: ventaja: pueden aprender cualquier correspondencia entre datos de entrada y resultado a predecir